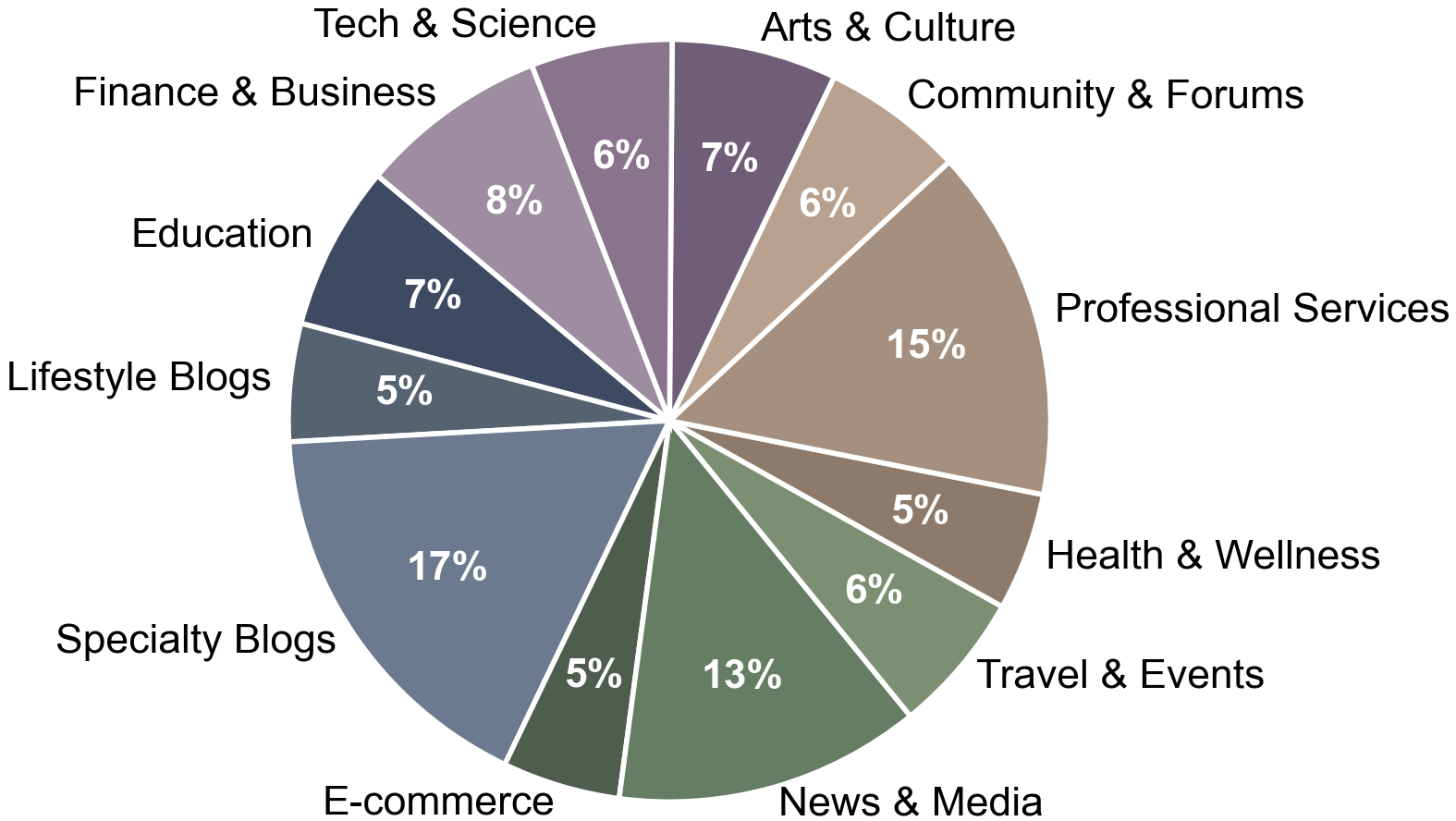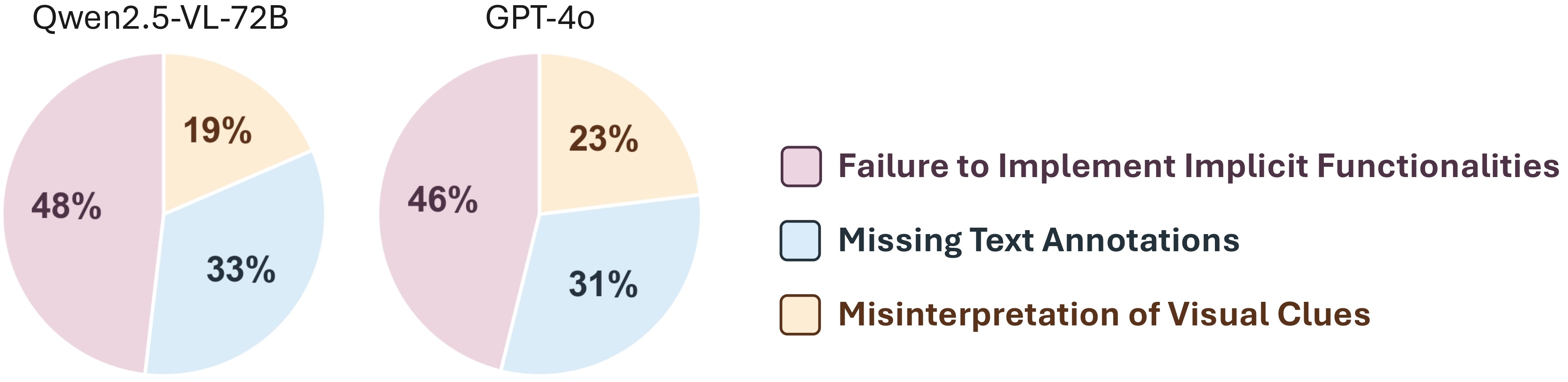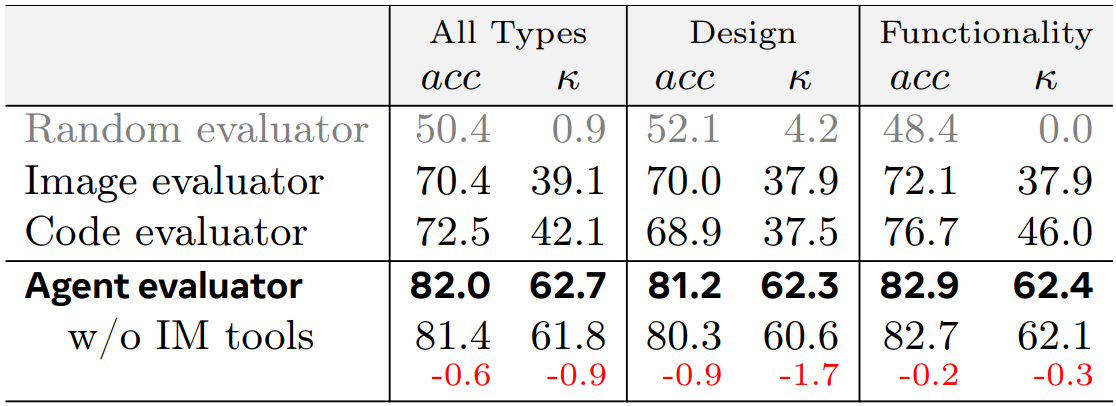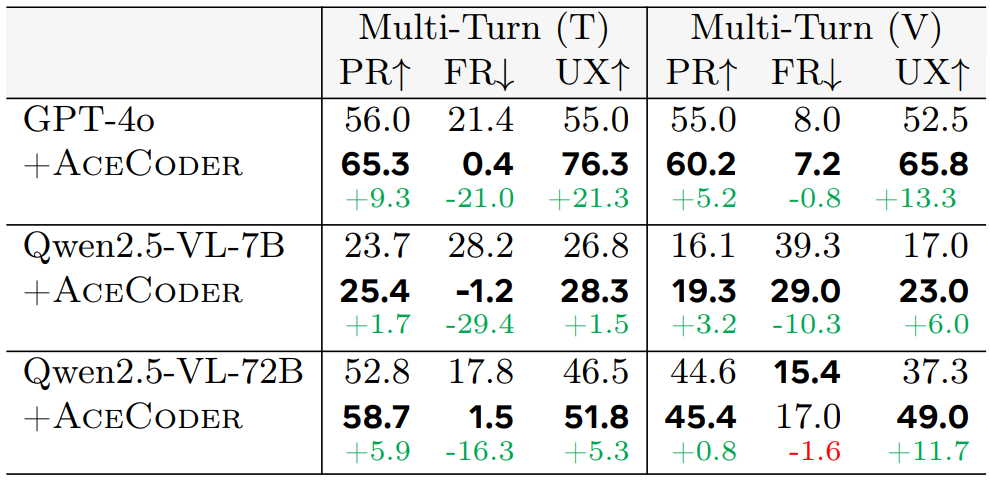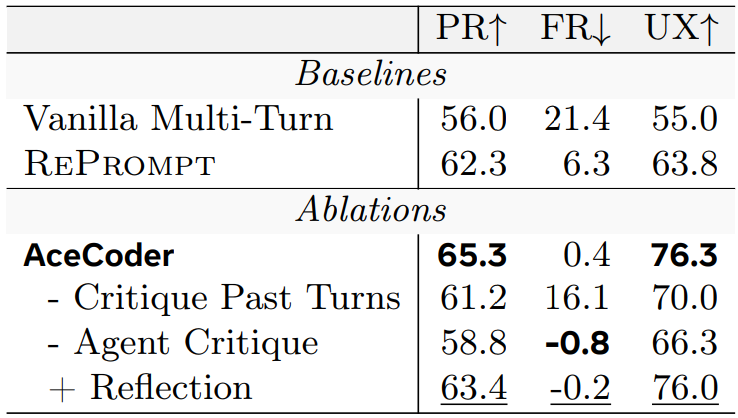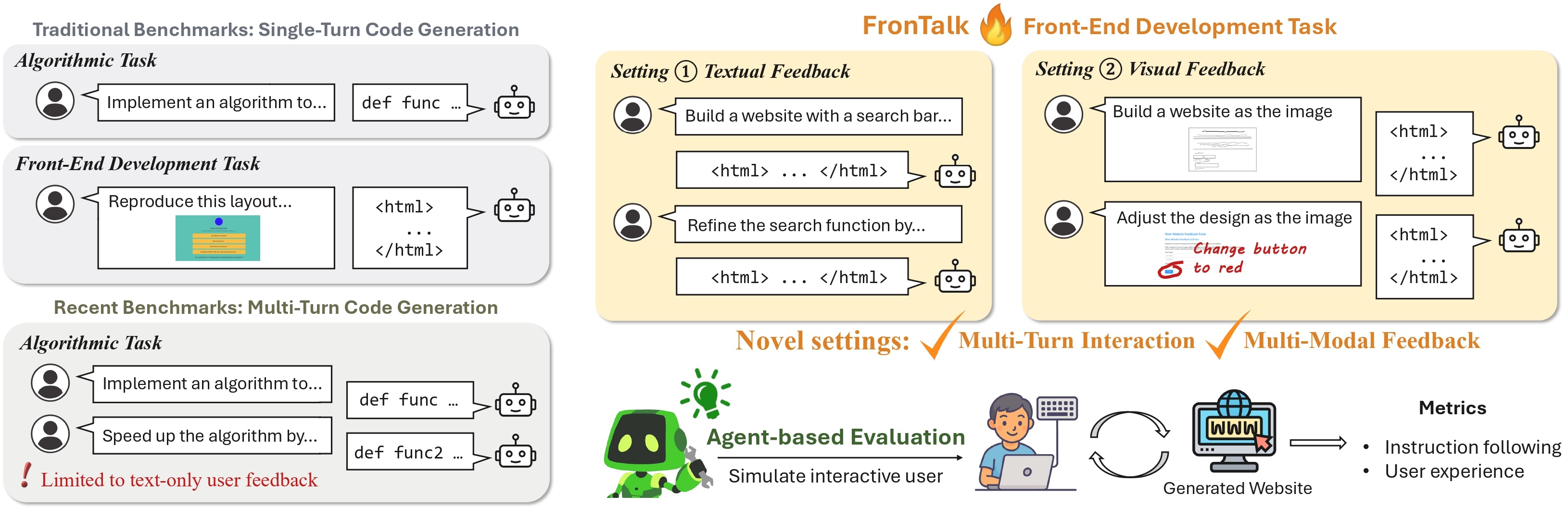
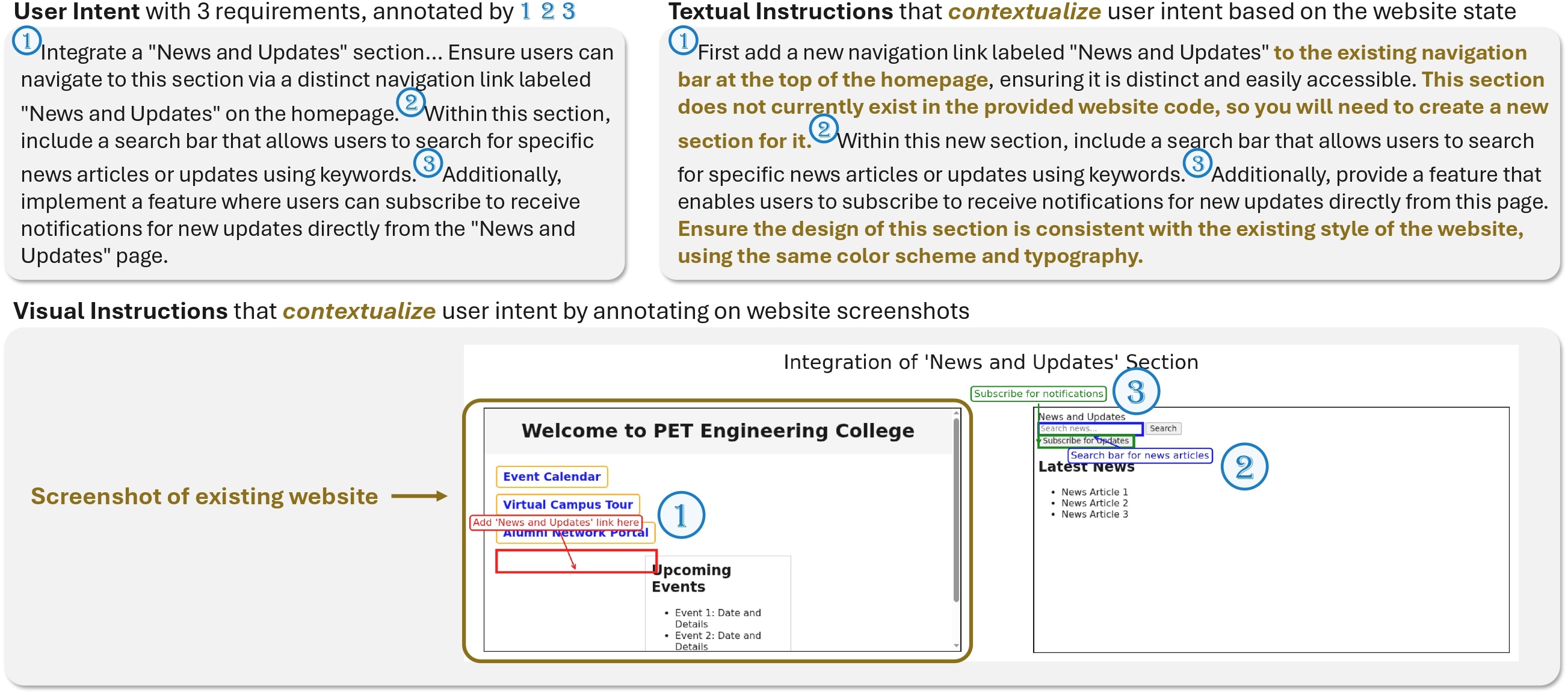
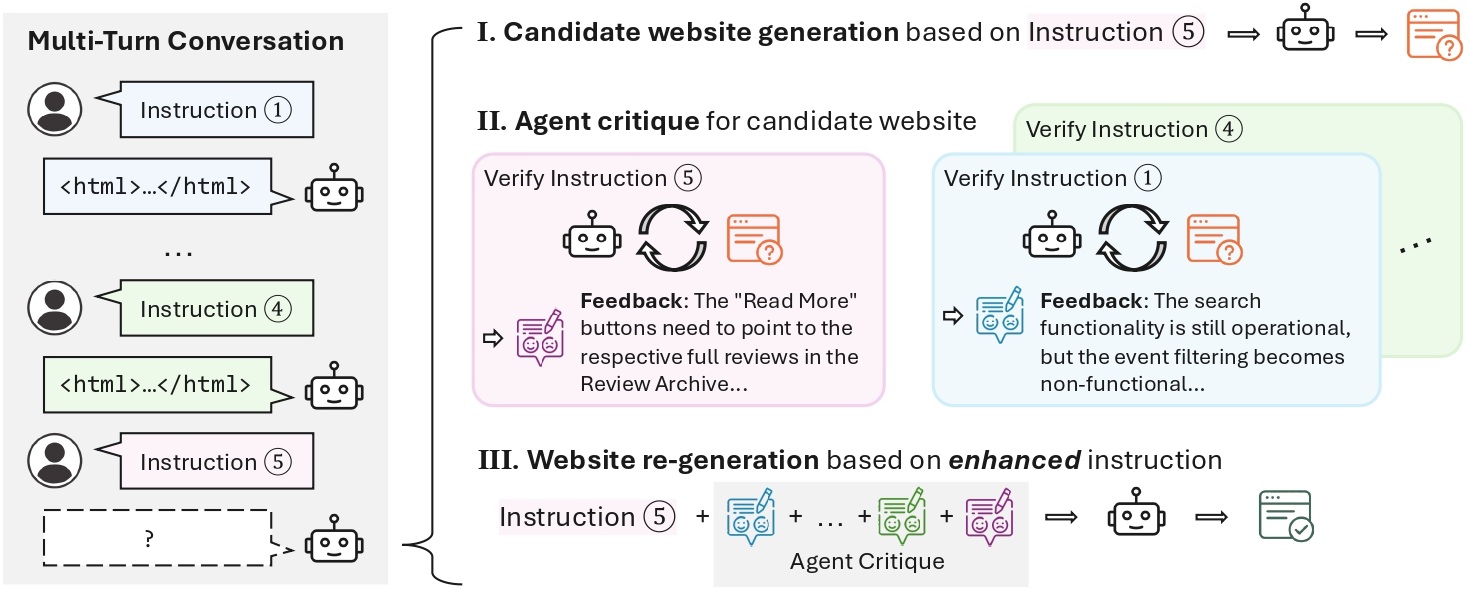
| # | Model | Single-Turn | Multi-Turn (Textual) | Multi-Turn (Visual) | |||||
|---|---|---|---|---|---|---|---|---|---|
| PR↑ | UX↑ | 🏅PR↑ | FR↓ | UX↑ | PR↑ | FR↓ | UX↑ | ||
| 1 | Gemini-2.5-Pro 🥇 | 57.2 | 56.8 | 75.0 | 4.5 | 71.0 | 68.7 | 6.2 | 73.8 |
| 2 | Qwen3-Coder-480B 🥈 | 67.0 | 64.0 | 62.5 | 15.4 | 62.3 | |||
| 3 | GPT-OSS-20B 🥉 | 64.3 | 68.5 | 61.6 | 15.8 | 71.5 | |||
| 4 | Qwen3-Coder-30B | 54.1 | 49.8 | 61.0 | 8.6 | 54.3 | |||
| 5 | Qwen3-8B | 54.3 | 45.8 | 59.9 | 13.9 | 57.8 | |||
| 6 | Qwen3-235B | 62.9 | 57.8 | 59.0 | 20.6 | 61.3 | |||
| 7 | GPT-OSS-120B | 68.0 | 73.5 | 57.9 | 9.2 | 66.8 | |||
| 8 | GPT-4o | 51.4 | 50.0 | 56.0 | 21.4 | 55.0 | 55.0 | 8.0 | 52.5 |
| 9 | Qwen3-VL-30B | 54.6 | 50.0 | 54.1 | 4.7 | 50.3 | 39.1 | 12.3 | 35.8 |
| 10 | Qwen2.5-VL-72B | 43.0 | 33.8 | 52.8 | 17.8 | 46.5 | 44.6 | 15.4 | 37.3 |
| 11 | Claude-4-Sonnet | 77.5 | 71.8 | 45.5 | 22.8 | 60.8 | 59.3 | 10.6 | 64.8 |
| 12 | Gemma3-12B | 47.1 | 43.5 | 43.8 | 30.3 | 43.0 | 30.4 | 22.1 | 38.5 |
| 13 | Gemma3-27B | 36.7 | 37.2 | 37.2 | 42.1 | 39.5 | 35.5 | 16.7 | 41.0 |
| 14 | Ovis2.5-9B | 51.5 | 49.3 | 35.3 | 12.2 | 34.3 | 27.0 | 10.5 | 39.5 |
| 15 | GLM-4.5V-108B | 24.4 | 23.5 | 35.2 | 9.8 | 40.5 | 7.9 | 27.7 | 7.8 |
| 16 | Qwen2.5-VL-32B | 44.5 | 38.0 | 33.2 | 46.9 | 37.5 | 36.9 | 25.7 | 36.5 |
| 17 | Llama-3.3-70B | 38.4 | 35.8 | 28.9 | 46.3 | 40.8 | |||
| 18 | DeepSeek-R1-685B | 60.0 | 53.5 | 24.7 | 34.5 | 40.0 | |||
| 19 | Qwen2.5-VL-7B | 24.5 | 19.5 | 23.7 | 28.2 | 26.8 | 16.1 | 39.3 | 17.0 |
| 20 | GLM-4.1V-Thinking-9B | 36.6 | 32.3 | 18.2 | 5.8 | 41.5 | 15.3 | 4.3 | 32.0 |
🚨 To submit your results to the leaderboard, please send to this email with the zip file of your outputs.